
Announcing Helix 1.0 – Secure Local GenAI for Serious People
We make Open Source Models work for you. Build AI Apps with Tools, RAG and Fine-Tuning


"We chose Helix because it worked out of the box, and the team shipped incredibly quickly and were very aligned with our ways of working”
– Marten Schönherr, CEO at AWA.network (watch interview)
When I told people I was going to build an OpenAI competitor you can run locally in 9 months with 4 part-time engineers and no funding, they told me I was crazy.
9 months later, and we’ve achieved the milestone of $100K in the bank from pure customer revenue. We’ve shipped a high performance GPU scheduler that can mix and match the latest LLMs from Ollama with image and fine-tuning jobs on any Docker or Kubernetes infrastructure and serve OpenAI-compatible API traffic at scale without missing a beat. We’ve built a beautiful web interface that allow business users to drag’n’drop to prototype RAG applications on top:

And with Helix Apps and AISpec (the latter in discussion to become a Linux Foundation project), we’ve created a totally new paradigm for how engineers and DevOps teams can and should version control and iterate on your LLM apps & infra. Our customers are already successfully using Helix Apps in production to iterate on their LLM applications to drive customer revenue in industries from construction and telco to marketing survey data, aerospace and healthcare.

For example, this HR app can be version-controlled as the following declarative configuration:

And today, we’re announcing Helix 1.0, because after a major refactor and months of hammering we are now declaring Helix stable and production-ready, ready for serious production use-cases.
Imagine what we’ll do in the next 9 months ;) But for now, let’s dive into Helix 1.0 and how it can help you bring serious GenAI capabilities within your own firewall…
Helix Architecture
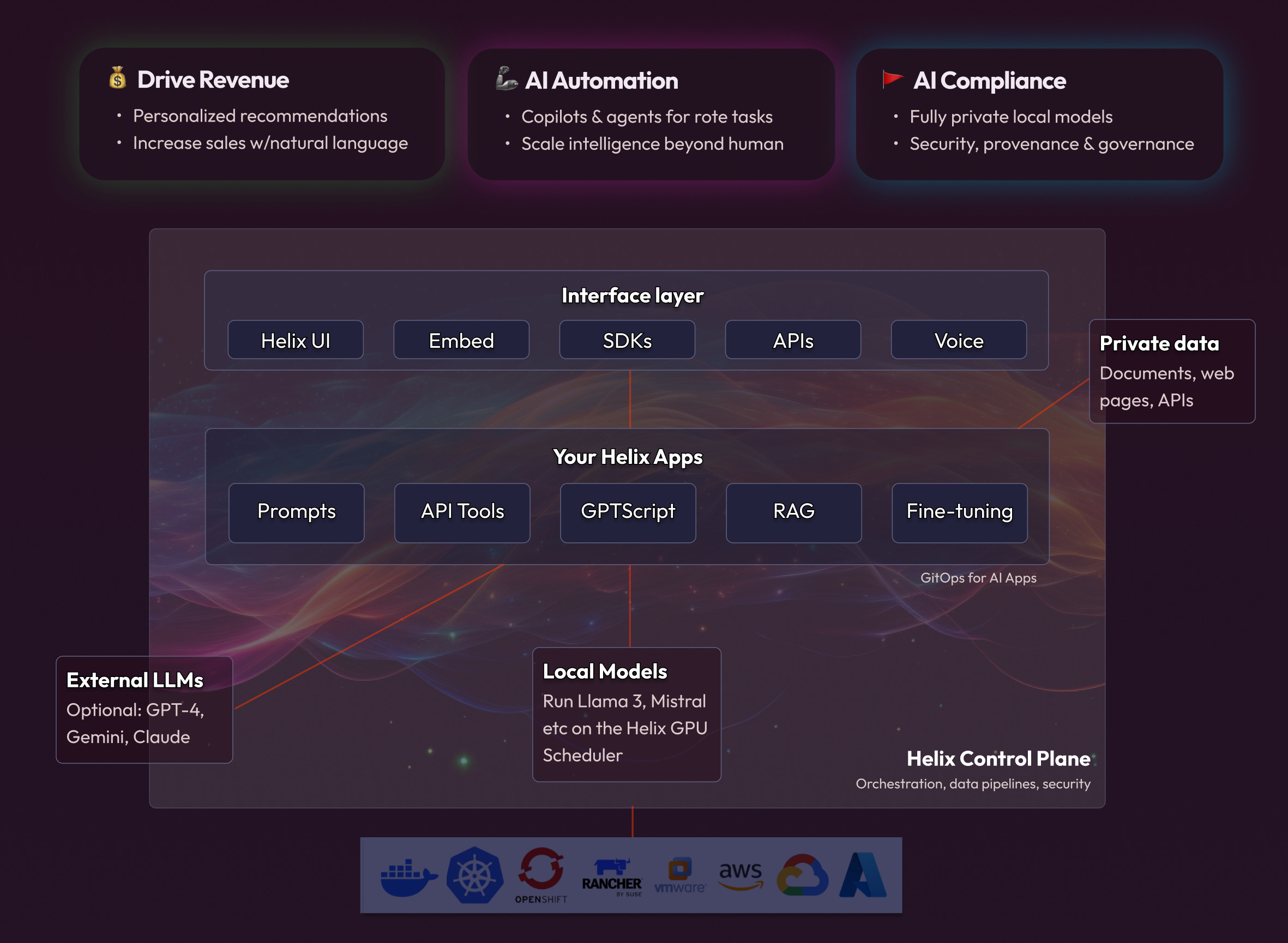
Helix is an uncomplicated stack of high quality components. It’s primarily written in Golang, the same language as Docker, Kubernetes and most of Google. This means it’s ridiculously easy to run locally and, unlike pure Python solutions, scales nicely in production. It integrates with Keycloak for identity and access control, and so integrates easily into everything from Okta to ActiveDirectory and OAuth, and it’s containerized, so it runs anywhere.
Conceptually, Helix consists of an interface layer and an app layer. These layers are independent. So, for example, you can have a RAG (app layer) chatbot which is exposed through the Helix UI (interface layer). Or you can have an API Tools integration (app layer) which is exposed through an OpenAI-compatible API.
You can even have a gptscript app for interacting with Terminal commands via a voice interface! Imagine being able to phone a number, ask “how much disk space do I have left”, and gptscript executes df -h on your runner and summarizes the result back to you :) You can build all of this just by building apps in Helix – either via the web interface or by writing yaml and pushing it to git (think Heroku for GenAI) or by using the CLI.
Interface Layer
Helix UI: we have a beautiful web interface that you can whitelabel that gives you the same capabilities as ChatGPT, but running locally on your own infrastructure (e.g. your own cloud account or data center) so that e.g your legal team can safely query over classified documents etc.
Embed: We have an embed widget that allows you to drop Helix-powered chat interfaces into any website or web application, internal or external. It’s available as an HTML <script> tag and a React component.
SDKs: We offer a Javascript/Typescript SDK for calling into Helix apps programmatically from a frontend application. This means you can build sophisticated, natural language powered experiences like recommendation systems beyond chatbots directly from the frontend.
APIs: We offer an OpenAI-compatible API to the app layer. This is actually super important. Our customers love the fact that they can swap in existing code they’ve built against OpenAI and make it work with Helix. What’s more, if you think about a llamaindex RAG setup, it doesn’t give you a frontend or a streaming API. The OpenAI chat completions API gives you that, with RAG or API tools implemented seamlessly underneath, plus an entire ecosystem of SDKs in every language. If it works with OpenAI, it works with Helix. We also offer our own sessions, fine-tuning and image gen APIs.
Voice: By integrating with Vocode, you can drive voice experiences directly against Helix Apps. So, you can configure a voice agent to sell car insurance directly from a Helix app with an API integration to the underlying quotes and billing APIs. Or you can power a voice interface to a product catalog to scale your sales team, just like our customers are doing.
Slack: Helix also has native support for Slack and Discord, so you can bring the conversation to where your team already are. Via our partners at Mation (Automatisch) we also support WhatsApp, SMS and just about any other interface you can imagine.
Helix Apps
The app layer is where the business logic happens. It takes an incoming request, such as an OpenAI chat completions request saying “what laptops do you have in the product catalog?” and passes it through the following sub-systems:
Prompts and Models: You can define system prompts to adjust the behavior of the model. You also define which model is used, we support everything on Ollama and Replicate.
API Tools: You can connect your app with APIs via an OpenAPI spec. Given a user query, we run it through three steps:
is_actionable: A classifier. Is this user trying to do something which requires an API call? If no (“hi, my name is Luke”), just process it with a regular inference call. If yes, proceed to the next step.prepare_api_request: Given an OpenAPI (Swagger) spec, construct an API call that captures what the user wants to do. E.g., “I want to buy a new laser printer”. The system then makes the API call on behalf of the user.interpret_response: Given the API response, summarize the response back to the user. “We have these laser printers available, do you need black and white or color?”
These prompts can be customized in the helix yaml (see below) to enable advanced use cases such as “translate the search terms into German before submitting them to the API” or “all prices are in €”. Plus the ability to give the system additional nudges on how to handle the API.
GPTScript: We’ve deeply integrated gptscript into Helix to make it the best place to run gptscript in production. GPTScript is a project from the Rancher founders, who were the biggest commercial success story of the Kubernetes ecosystem.
RAG and Knowledge: We’ve got pgvector and llamaindex plugged in to enable easy, out of the box knowledge and retrieval. With knowledge, you can even specify a website, S3 bucket, Google Drive or OneDrive and we’ll automatically scrape it for you, and refresh it on a schedule.
Fine-tuning: We support the easiest-to-use workflow to fine-tune your own LLM on your private data: we’ll take raw documents and use an LLM (also running privately) to generate training data from those documents. Then we’ll train the model locally using axolotl on the same fleet of GPUs you use for inference. Then, you can serve up that customized model that has been taught about your specific knowledge domain just like any other Ollama model.
Infrastructure Layer
We have two options for the underlying inference stack:
Local models: You can run the Helix runner container on your own GPUs and get all of the features above, fully privately.
External LLMs: Some customers have already selected an LLM provider such as Azure OpenAI, Gemini, Claude or already run their own vLLM. Helix supports proxying to those backends, providing a central control location to give your employees access to these models while still retaining the observability and control that you need to safely leverage AI.
You can mix and match these options, so you can use fully private open source LLMs for sensitive use cases, and give other projects access to Claude or OpenAI where those models offer additional benefits.
In terms of underlying infrastructure, Helix can be deployed as a simple Docker Compose stack, or via our Helm chart on Kubernetes.
Private LLMs for your existing apps in Kubernetes
Deploying Helix to a Kubernetes cluster and then deploying your own llamaindex or langchain apps to that same cluster is a natural fit, since you can then securely access the LLM endpoints that Helix provides over the private Kubernetes network.
LLMOps and GitOps
Helix supports three ways to deploy Helix Apps:
Via the web interface. Anyone in your business can set up a Helix app, with avatar, system prompt, knowledge and integrations, by clicking buttons in the web interface. Under the hood, these apps are version controlled and can be exported by the DevOps team into version controlled yaml.
Via GitHub integration. We offer a simple GitHub integration so you can create GitHub OAuth App and then connect Helix to it. Users can then select repos they have access to in GitHub and then every time they push to the main branch, the Helix App is automatically deployed.
Via CLI. We offer a
helix apply -fstyle CLI that allows you to deploy any helix yaml to your system just with an API key in an environment variable. As well as fast local iteration, this allows you to set up more sophisticated workflows from CI/CD such as automatically deploying branches to a preview app, where you can then run evals on them side by side.
Helix Apps have their own dedicated API keys which allow you to select the app simply by sending requests to the OpenAI compatible API with that key – the OpenAI API will magically act as configured, replete with knowledge, API integrations and so on.
Evals integration
Helix supports integrations with all major evals tools, and in particular we can recommend DeepEval. Combined with the CI/CD integration above, you can achieve the nirvana of automatic testing of your LLM app every time you change a single word in the prompt.
Try it today
Read the vision blog and take a look at the website
Book a demo with Chris, who is awesome, by emailing founders@helix.ml
Kick the tires on the SaaS, then install it yourself on any Linux/macOS/WSL2 machine with:
curl -sL -O https://get.helix.ml/install.sh && bash install.sh
If you are in San Francisco on Sep 12, join us at Making Open Source and Local LLMs Work in Practice x MLOps Community!
Cheers,
Luke