
GPU Virtualization Architecture for Multi-Desktop Containers
I thought we'd have this working by now...

Overview
Helix Desktop runs multiple isolated Linux desktop environments (each with its own GNOME Shell, IDE, and browser) inside a single QEMU virtual machine on Apple Silicon Macs. Each desktop gets its own virtual GPU output, H.264 video stream, and DRM lease — all sharing one physical GPU through virtio-gpu with Vulkan passthrough via Venus/virglrenderer.
This document describes the full architecture from silicon to pixel, and the deadlock bugs we found and fixed when scaling from 1-2 desktops to 4+.
Why This Matters
AI agents are getting good enough to write real code, but they still need somewhere to run it. Not just a terminal — a full desktop environment with a browser for testing, an IDE for human pair programmers, and GPU acceleration for anything graphical (and hardware video encoding for low latency when a user wants to pair with them over the network). And when you have a team of agents working on different tasks, each one needs its own isolated sandbox so they don’t step on each other’s files, processes, or state.
Helix Desktop gives every agent its own full Linux desktop — running in an isolated container with GPU acceleration. Humans can watch what their agents are doing in real time via H.264 video streams, jump in to collaborate through the same desktop interface, and manage their flock of agents from a mobile phone while on the go. Think of it as giving each agent their own workstation in a virtual office, where you can glance at any screen and tap on it to intervene.
This architecture also enables new human-computer interaction patterns: commentable spec-driven development where a human writes requirements in a Google Docs-style document, agents immediately update their design docs in response to comments, and the human reviews and redirects — all happening concurrently across multiple agent desktops. The agents work in parallel, each in their own sandbox, while the human herds the flock.
The hard technical problem: running 4+ GPU-accelerated desktops simultaneously inside a single QEMU virtual machine on Apple Silicon, sharing one physical GPU, without them deadlocking each other. That’s what this document is about.
The Stack
Browser (WebSocket H.264 client)
|
Helix Frame Export (VideoToolbox H.264, per-scanout)
|
QEMU virtio-gpu device model (fence_poll, process_cmdq, scanout management)
|
virglrenderer (Venus proxy — Vulkan API translation, runs as separate process)
|
Apple Metal / ParavirtualizedGraphics (actual GPU execution)
|
Apple M-series GPU silicon
On the guest side:
Container (gnome-shell + Zed IDE + browser)
|
DRM lease FD (connector + CRTC + planes)
|
virtio-gpu kernel driver (DMA fences, GEM objects, atomic modesetting)
|
virtio control queue (1024-entry ring buffer to QEMU)
Layer 1: The Virtio Control Queue
The guest Linux kernel’s virtio_gpu driver communicates with QEMU through a virtio virtqueue — a shared-memory ring buffer. The guest writes command descriptors (create resource, submit 3D command batch, map blob, set scanout, etc.) and kicks the queue. QEMU receives the kick as a vmexit on Apple’s Hypervisor.framework, pops commands from the ring, and processes them.
There are two queues: control (all GPU commands) and cursor (cursor image updates). The control queue is the bottleneck.
Sizing matters. The default queue size is 256 entries for 2D mode, which we increased to 1024 (the virtio maximum) for 3D/GL mode. With 4 gnome-shells each submitting GPU commands continuously, 256 entries fills up. When the ring is full, guest threads block in virtio_gpu_queue_ctrl_sgs — a kernel spinwait that shows up as permanent D-state processes. 1024 entries gives enough headroom.
Command Response Flow
Guest kernel QEMU (main thread)
============ ==================
write cmd to ring
virtqueue_kick() ──vmexit──> virtio_gpu_handle_ctrl_cb()
qemu_bh_schedule(ctrl_bh)
...main loop iteration...
virtio_gpu_gl_handle_ctrl()
virtqueue_pop() -- dequeue all pending
QTAILQ_INSERT_TAIL(&cmdq)
virtio_gpu_process_cmdq()
for each cmd in cmdq:
process_cmd(cmd) -- dispatch
if fenced: move to fenceq
if finished: send response
virtio_gpu_virgl_fence_poll()
virgl_renderer_poll() -- check GPU
process_cmdq() again
re-arm timer
<──interrupt── virtio_notify()
dma_fence_signal() (response written to reply ring)
The critical thing: every command gets exactly one response. The guest thread that submitted it blocks in the kernel until that response arrives as a virtio interrupt. If QEMU never processes the command, the guest thread blocks forever.
Layer 2: QEMU’s Command Processing Pipeline
QEMU maintains two queues:
cmdq: Commands popped from the virtio ring, waiting to be dispatched to virglrendererfenceq: Commands that have been dispatched but are waiting for GPU completion (async)
And one critical counter:
renderer_blocked: A global semaphore. When >0,process_cmdq()refuses to process ANY command from ANY context.
The renderer_blocked Problem
renderer_blocked was designed for SPICE’s GL display path. When SPICE blits a frame to the client, it calls graphic_hw_gl_block(true) to pause GPU command processing until the client acknowledges the frame (gl_draw_done). This makes sense for a single display — you don’t want the GPU racing ahead while the display catches up.
But renderer_blocked is global across all scanouts. With 4 gnome-shells, if scanout 1’s SPICE client is slow to acknowledge, ALL four desktops freeze. Worse, blob resource unmaps (Venus uses these heavily for Vulkan memory management) were also incrementing renderer_blocked during their async RCU cleanup phase. With 4 contexts doing overlapping blob unmaps, the counter stayed >0 perpetually.
Fix: We removed renderer_blocked from the blob unmap path entirely. The suspended-command mechanism (cmd_suspended flag + continue in the FOREACH loop) already prevents the specific unmap command from re-executing before RCU completes, without blocking commands from other contexts. We also skip dpy_gl_update entirely on Apple builds (Helix frame export handles frame capture directly, bypassing SPICE).
The process_cmdq FIFO Blocking Problem
The original process_cmdq used QTAILQ_FIRST + break when it encountered a suspended command:
// OLD (broken with 4+ contexts):
while (!QTAILQ_EMPTY(&cmdq)) {
cmd = QTAILQ_FIRST(&cmdq);
process_cmd(cmd);
if (cmd_suspended) break; // STOPS ALL PROCESSING
...
}A single suspended blob unmap from context 1 would block commands from contexts 2, 3, and 4 that are sitting later in the queue.
Fix: Changed to QTAILQ_FOREACH_SAFE with continue — suspended commands stay in the queue but later commands are processed normally.
Layer 3: Fences and the Poll Timer
When a guest submits a GPU command with VIRTIO_GPU_FLAG_FENCE, QEMU dispatches it to virglrenderer and moves it to fenceq. The command stays there until virglrenderer reports that the GPU finished the work.
virglrenderer reports fence completion via a callback (virgl_write_fence), but this callback only fires when QEMU calls virgl_renderer_poll(). And virgl_renderer_poll() only gets called from two places:
handle_ctrl— when the guest kicks the virtqueue (submits new commands)fence_poll— a periodic timer callback
The fence_poll timer is supposed to fire every 10ms (100 Hz). Each invocation:
Calls
virgl_renderer_poll()— asks virglrenderer “any fences done?”Calls
process_cmdq()— processes any queued commandsRe-arms itself for 10ms later
Why the Timer Matters
Without fence_poll, fence completions only get checked when the guest submits new commands (via handle_ctrl). But if the guest is waiting for a fence to complete before submitting the next command, there’s a circular dependency:
Guest: "I'll submit my next command after fence 42 completes"
QEMU: "I'll check if fence 42 completed when I get the next command"
The timer breaks this cycle by polling independently.
The Virtual Clock Problem
The original code used QEMU_CLOCK_VIRTUAL for the timer. This clock tracks virtual CPU time — it stops advancing when all vCPUs are halted (executing WFI/wait-for-interrupt). When all guest threads are blocked on GPU fences, all vCPUs eventually enter WFI, the virtual clock stops, and fence_poll never fires. The fences never complete, the vCPUs never wake up — permanent deadlock.
Fix: Switch to QEMU_CLOCK_REALTIME which always advances regardless of vCPU state. Also make the timer unconditionally re-arm (the original code only re-armed when there was work to do, but there was a race window between “work arrives” and “timer checks”).
The Mystery: REALTIME Timer Still Doesn’t Fire
After switching to QEMU_CLOCK_REALTIME, fence_poll still shows zero hits in 1-second process samples (782 samples at 1ms intervals). Meanwhile, gui_update — also a REALTIME timer — fires 3-4 times per second from the exact same timerlist_run_timers call path. Both timers are created with timer_new_ms(QEMU_CLOCK_REALTIME, ...) so they should be on the same timerlist. We confirmed via QEMU logs that virtio_gpu_virgl_init runs (twice, due to a guest driver reset/re-init cycle) and reaches the timer_new_ms + timer_mod calls.
The QEMU main loop thread spends 768/782 samples idle in g_poll → __select. During the 14 active samples, 3 go through qemu_clock_run_all_timers → timerlist_run_timers → gui_update. Zero go through fence_poll. All 14 vCPU threads show heavy BQL contention (25-60% of samples in bql_lock_impl).
The QEMU logs show Blocked re-entrant IO on MemoryRegion: virtio-pci-notify-virtio-gpu which means virtio_notify() — called from process_cmdq() → virtio_gpu_ctrl_response() when completing a command — is hitting QEMU’s memory region re-entrancy guard. The guard silently returns MEMTX_ACCESS_ERROR, dropping the guest notification. This could cascade: if the dropped notification means a guest interrupt never fires, the guest thread stays blocked, the vCPU stays in WFI, and the circular dependency persists.
However, this doesn’t explain why the timer itself doesn’t fire. The re-entrancy affects notifications inside process_cmdq, not the timer scheduling. The timer should fire regardless of what happens inside its callback — the callback runs, re-arms via timer_mod, and the main loop picks it up next iteration.
Root cause remains unknown. The difference between gui_update (fires) and fence_poll (doesn’t fire) may be related to when the timer is created: gui_update is created during display initialization before the main loop starts, while fence_poll is created lazily during handle_ctrl (first virtqueue kick) after the main loop is already running. There may be a timer registration race in QEMU’s GLib integration.
The Workaround: Thread-Based Fence Polling
Rather than continuing to debug QEMU’s timer internals, we bypass the timer system entirely with a dedicated thread:
/* Thread function — runs independently of QEMU’s main loop */
static void *fence_poll_thread_fn(void *opaque)
{
VirtIOGPU *g = opaque;
VirtIOGPUGL *gl = VIRTIO_GPU_GL(g);
while (gl->fence_poll_thread_running) {
g_usleep(10000); /* 10ms = 100 Hz */
qemu_bh_schedule(gl->fence_poll_bh);
}
return NULL;
}
/* BH callback — runs on main loop thread with BQL held */
static void fence_poll_bh_cb(void *opaque)
{
VirtIOGPU *g = opaque;
virgl_renderer_poll();
virtio_gpu_process_cmdq(g);
}The thread does nothing except sleep 10ms and schedule a bottom-half (BH) on QEMU’s main loop. qemu_bh_schedule() is documented as thread-safe — it writes to an eventfd that wakes the main loop from its g_poll. The BH dispatches on the main thread via aio_ctx_dispatch with BQL held, which is the correct context for virgl_renderer_poll() and process_cmdq().
This is robust because:
g_usleepalways works (no dependency on QEMU’s timer system)qemu_bh_schedulealways works (we see BH dispatch in the process samples)BH dispatch is the same mechanism used for virtio command processing
The original QEMU timer is kept as a secondary fallback — if it ever fires, extra
virgl_renderer_pollcalls are harmless
Layer 4: virglrenderer and Venus
virglrenderer translates Vulkan API calls from the guest into native Metal API calls on the host. It runs as a separate process (proxy mode) communicating with QEMU over a Unix socket. Each guest GPU context (one per gnome-shell) gets its own virglrenderer thread.
The flow:
Guest Mesa driver makes Vulkan calls
Venus (Vulkan-on-virtio-gpu protocol) serializes them into virtio-gpu
SUBMIT_CMDbatchesQEMU dispatches batches to virglrenderer via
virgl_renderer_submit_cmd()virglrenderer deserializes and calls Metal/MoltenVK equivalents
When GPU work completes, virglrenderer reports via
virgl_write_fence()callback
Venus heavily uses blob resources — guest-visible GPU memory objects. Creating and destroying these involves RESOURCE_CREATE_BLOB and RESOURCE_UNMAP_BLOB commands. The unmap path is particularly tricky because it requires RCU (read-copy-update) synchronization to safely remove memory regions, which is what led to the suspended-command mechanism.
Layer 5: DRM Leases
Each agent’s container needs exclusive access to a virtual GPU output — its own screen, essentially. When a human starts a new agent session, the system needs to dynamically provision a virtual display, hand it to the agent’s container, and start streaming video from it. When the agent’s session ends (or crashes), the display is reclaimed and recycled. This has to work for 15+ concurrent agents on a single machine.
Linux DRM leases provide the isolation primitive: the DRM master can carve off subsets of its resources and hand them to clients as independent DRM file descriptors.
The helix-drm-manager runs as a systemd service on the guest VM:
Opens
/dev/dri/card0as DRM masterEnumerates connectors and CRTCs (virtio-gpu creates 16 virtual outputs)
Listens on a Unix socket for lease requests from containers
For each request:
Allocates a scanout index (1-15; 0 is the VM console)
Tells QEMU to enable that scanout (TCP message to frame export server)
Creates a DRM lease (connector + CRTC + primary plane + cursor plane)
Sends the lease FD to the container via
SCM_RIGHTS
Monitors the connection — when the container dies, automatically revokes the lease and disables the scanout
The mode_config.mutex Deadlock
Two operations in the DRM manager acquired the kernel’s mode_config.mutex:
activateCrtc—DRM_IOCTL_MODE_SETCRTCon the master FD to pre-initialize the CRTC before handing the lease to mutterreprobeConnector— writing to/sys/class/drm/card0-Virtual-N/statusto trigger connector detection
Running gnome-shells also hold mode_config.mutex during atomic page flips (drm_atomic_commit). If a gnome-shell is mid-commit waiting for a GPU fence (which may be stalled due to the fence_poll issue), it holds the mutex indefinitely. The DRM manager trying to set up a new lease blocks on the same mutex, and all other gnome-shells’ page flips cascade-block behind it.
Fix: Removed both activateCrtc and reprobeConnector. QEMU’s enableScanout already triggers the guest hotplug event via dpy_set_ui_info, so the connector appears without explicit reprobe. Mutter can do its own initial modeset through the lease FD now that DRM_CLIENT_CAP_UNIVERSAL_PLANES is set on the master.
Layer 6: Frame Export and Video Streaming
The Helix frame export system (helix-frame-export.m) captures GPU frames directly from QEMU and encodes them as H.264 video:
Capture: When virglrenderer flushes a scanout, QEMU’s
virgl_cmd_resource_flushcalls into helix frame export. The frame’s Metal texture handle is extracted directly from virglrenderer’s native handle — zero CPU copies.Blit: The Metal texture is blitted to an IOSurface via EGL/GL. Triple buffering (3 IOSurface slots per scanout) allows VideoToolbox to encode asynchronously without blocking the GPU.
Encode: Apple’s VideoToolbox hardware H.264 encoder compresses each IOSurface. The encode callback fires on a VT thread, which schedules a BH (bottom-half) on QEMU’s main thread to send the encoded frame.
Send: Encoded NAL units are sent to subscribed clients over TCP sockets. Each client subscribes to a specific scanout. Frames are dropped (not queued) if the client’s send buffer is full — this prevents one slow client from affecting others.
The frame export explicitly avoids renderer_blocked / gl_block. The old SPICE GL path used renderer_blocked for backpressure (pause GPU until client acknowledges frame), which is global and causes cross-scanout stalls. Instead, the frame export uses per-slot busy flags — if all 3 IOSurface slots for a scanout are busy with VT encoding, that scanout’s frames are dropped, but other scanouts continue normally.
Why Scaling Matters
A single desktop works fine. Two work fine. The deadlocks only appear at 4+ concurrent desktops — which is exactly the regime we need for production use. A developer working with a team of agents will routinely have 4-8 agents running simultaneously: one refactoring the backend, one writing frontend tests, one investigating a bug, one updating documentation. Each needs a responsive GPU-accelerated desktop. If starting the fourth agent freezes the other three, the product doesn’t work.
Every fix described below was discovered by starting 4 desktops in quick succession and tracing kernel stacks, QEMU process samples, and /proc/interrupts to find exactly where the system seized up. The bugs are all variations of the same theme: mechanisms designed for a single GPU context becoming global bottlenecks when shared across many.
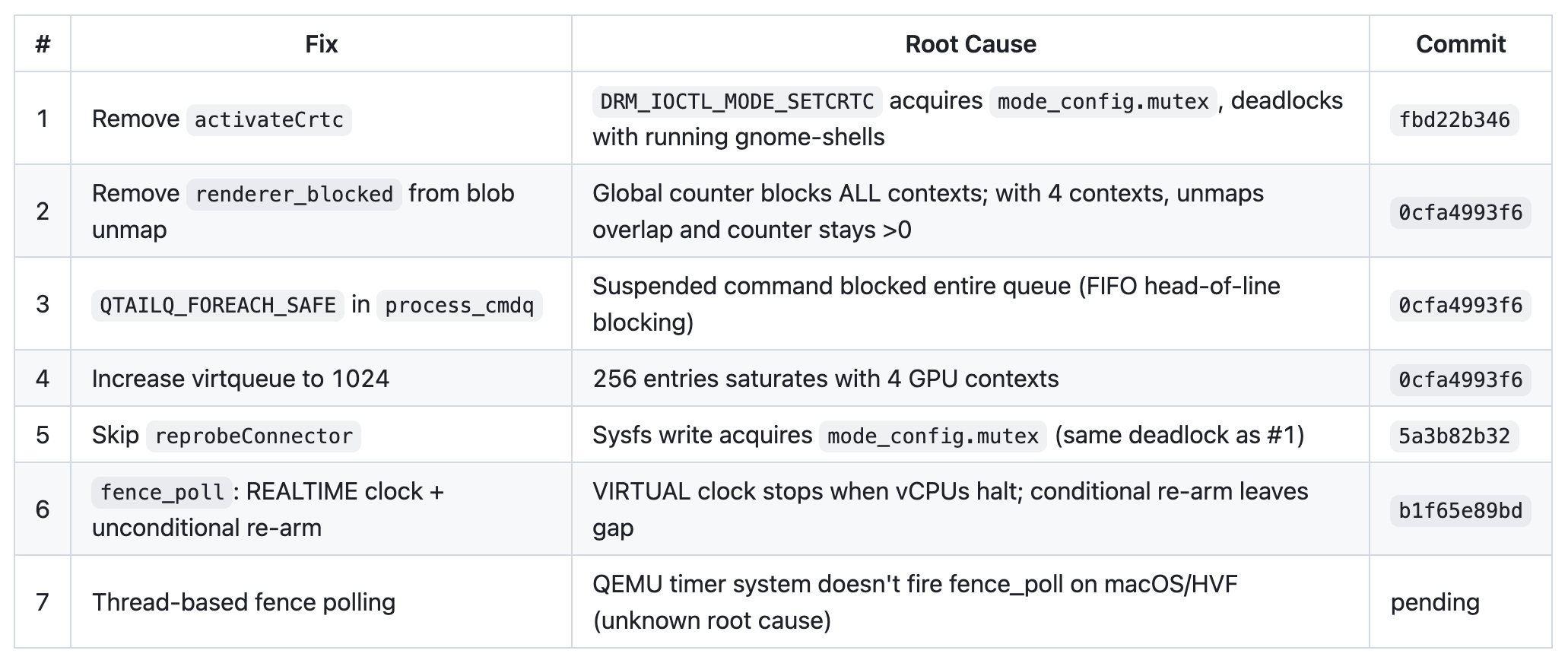
Summary of Fixes
Will we fix it? Stay tuned to find out :-D
The Debugging Method
Every fix was discovered the same way: start 4 desktops in quick succession, then trace the freeze:
/proc/interrupts— check if GPU interrupt count (virtio1-control) is advancing. If frozen (same count 5 seconds apart), QEMU isn’t sending fence completions to the guest.cat /proc/*/stack— find D-state processes. gnome-shells stuck indrm_modeset_lock→dma_fence_default_waitmeans they’re waiting for GPU fences while holdingmode_config.mutex. Anything stuck invirtio_gpu_vram_mmapmeans a synchronous MAP_BLOB is waiting for QEMU to process it.sample <pid> 1(macOS) — 1-second process sample of QEMU at 1ms intervals. Shows where every thread spends its time. The main loop thread should showfence_pollorprocess_cmdqhits; if it’s 100% ing_poll, nothing is processing GPU commands.Kernel hung task messages (serial console) —
task X:PID is blocked on a mutex likely owned by task Y:PIDdirectly identifies which process holds the contended lock.QEMU warnings —
Blocked re-entrant IO on MemoryRegionmeans avirtio_notifywas silently dropped, which means a guest never received a response for a command it’s waiting on.