
How We Forked Zed and Added Remote Control for Agent Fleet Orchestration

Zed is a fast, GPU-accelerated code editor written in Rust. It has excellent LSP support, a growing agent panel, and a clean architecture. It also has no concept of external orchestration — and that’s where our problem started.
Helix runs fleets of coding agents. Each agent is a headless Zed instance running inside a Docker container, connected to an LLM via the Agent Control Protocol (ACP). A central API dispatches tasks, monitors progress, manages thread lifecycles, and streams results back to users in real time. None of that is possible with stock Zed — so we forked it and added a WebSocket control plane.
This post covers what we built, the bugs that nearly broke us, and how we got streaming performance from O(N²) down to O(delta).
What We Needed From the Fork
Three capabilities required forking:
Remote command injection — the API must be able to send chat messages, simulate user input, and query UI state in a running Zed instance, with no human at the keyboard.
Event exfiltration — Zed must report back when a thread is created, when messages stream in, when the agent finishes, and when errors occur.
Multi-thread lifecycle management — when a thread exhausts its context window, Helix starts a new one on the same WebSocket connection. Zed must handle multiple concurrent ACP threads per connection.
The WebSocket Sync Protocol
The control plane is a single bidirectional WebSocket between the Helix API and each Zed instance. The API side lives in websocket_external_agent_sync.go; the Zed side in crates/external_websocket_sync/.
Server → Zed (commands):

Zed → Server (events):
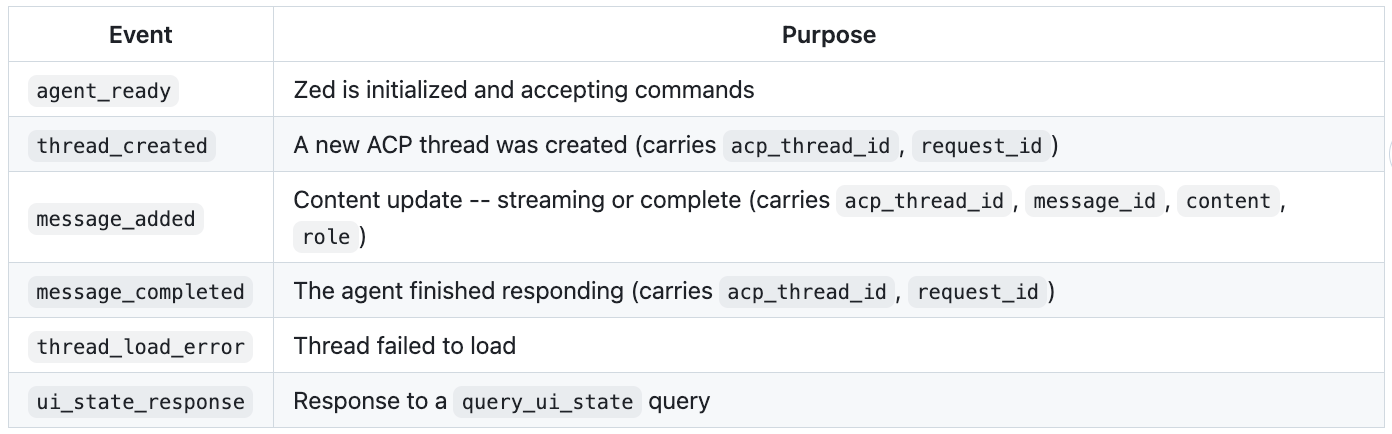
Every message that touches a thread carries acp_thread_id for correlation. The request_id field ties a command to its eventual thread_created and message_completed events, so the API can track which user request produced which response.
Architecture
Helix Frontend
|
| HTTP POST /api/v1/sessions/chat
v
Helix API ----WebSocket----> Zed (headless, in container) ---ACP---> LLM
| |
| pubsub (session_update, | thread events
| interaction_update) | (message_added, etc.)
v |
Helix Frontend <----WebSocket--------+The API maintains a map of acp_thread_id to Helix session IDs. When a user sends a message, the API creates an Interaction record with the user’s prompt, then dispatches a chat_message command over the WebSocket. Zed creates or reuses an ACP thread, the LLM streams its response, and Zed relays each chunk back as message_added events. The API accumulates these into the Interaction’s response and publishes real-time updates to the frontend.
When context exhausts, Helix sends a new chat_message without an acp_thread_id, prompting Zed to create a fresh thread. The new thread_created event maps it back to the same Helix session. One WebSocket connection manages the full lifecycle.
Bug 1: The Multi-Message Accumulation Problem
Zed’s agent panel produces multiple distinct entries per response turn: an assistant message, one or more tool calls, and a follow-up message. Each entry has its own message_id. Within a single entry, Zed streams cumulative content updates — the full content so far for that entry, not deltas.
The original code stored the response as a single string and overwrote it on each message_added event:
go
// The bug
interaction.ResponseMessage = contentFine when there’s one message_id. With multiple entries:
message_added(id="msg-1", content="I'll help you with that.")→ response ="I'll help you with that."message_added(id="msg-2", content="`tool\nedit")` → response = `"`tool\nedit"(msg-1 gone)message_added(id="msg-2", content="`tool\nedit file.py\n`")→ correct overwrite of msg-2, but msg-1 is still gone
The fix tracks the byte offset where each message_id‘s content begins. Same ID → replace from offset. New ID → append with separator, record new offset:
go
type MessageAccumulator struct {
Content string
LastMessageID string
Offset int // byte offset where current message_id starts
}
func (a *MessageAccumulator) AddMessage(messageID, content string) {
if a.LastMessageID == "" {
a.Content = content
a.Offset = 0
a.LastMessageID = messageID
return
}
if a.LastMessageID == messageID {
// Same message streaming -- replace from offset, keep prefix
a.Content = a.Content[:a.Offset] + content
return
}
// New distinct message -- record offset, append with separator
a.Offset = len(a.Content) + 2 // account for "\n\n"
a.Content = a.Content + "\n\n" + content
a.LastMessageID = messageID
}Zed sends cumulative content per message_id (overwrite semantics), but the overall response is an append-only sequence of distinct message IDs. The accumulator handles both with a single offset tracker.
Bug 2: The Completion Hang
Users reported that responses would stream correctly but never show as complete — the loading spinner hung indefinitely.
The handler for message_completed published session_update events to the frontend. The frontend’s session_update handler has rejection logic: it checks whether the incoming session has the expected number of interactions and drops events that fail validation. A safeguard against stale data from out-of-order WebSocket messages — but it meant completion events were intermittently discarded.
The fix was to publish through both channels:
go
// 1. interaction_update -- same channel used during streaming
// ensures useLiveInteraction sees state=complete
err = apiServer.publishInteractionUpdateToFrontend(
helixSessionID, helixSession.Owner, targetInteraction, messageRequestID)
// 2. session_update -- full session for React Query cache consistency
err = apiServer.publishSessionUpdateToFrontend(
reloadedSession, targetInteraction, messageRequestID)The interaction_update path targets a specific interaction rather than the full session, bypassing the rejection logic entirely. That’s the reliable path for completion signals.
Shared Protocol Code: Eliminating Test Drift
The original end-to-end tests used a Python mock WebSocket server that reimplemented the sync protocol. The accumulation bug above didn’t appear in tests because the Python mock had its own (simpler) message handling. Tests passed. Production broke.
The solution: extract a shared wsprotocol Go package that both the production Helix server and the Go test server import. Same parsing, same accumulation logic, same event dispatch. If the accumulator has a bug, the test catches it because it runs the same code path.
The package has four components. MessageAccumulator — the append/overwrite logic above. Protocol — manages the WebSocket lifecycle, reads and parses messages, dispatches to handlers. EventHandler interface — the seam between shared protocol code and environment-specific behavior:
go
type EventHandler interface {
OnAgentReady(conn *Conn, sessionID string) error
OnThreadCreated(conn *Conn, sessionID string, evt *ThreadCreatedEvent) error
OnMessageAdded(conn *Conn, sessionID string, evt *MessageAddedEvent, accumulated string) error
OnMessageCompleted(conn *Conn, sessionID string, evt *MessageCompletedEvent) error
OnUIStateResponse(conn *Conn, sessionID string, evt *UIStateResponseEvent) error
OnThreadLoadError(conn *Conn, sessionID string, evt *ThreadLoadErrorEvent) error
OnRawEvent(conn *Conn, sessionID string, msg *SyncMessage) error
}Production implements this with database writes and pubsub. Tests use in-memory tracking and assertions. The OnRawEvent escape hatch handles Helix-specific events without bloating the shared interface.
Adding a new event type: (1) add a struct to types.go, (2) add a case to dispatch, (3) add a method to EventHandler. Both production and test code get the change, or neither does. No more protocol drift.
Streaming Performance: O(N²) to O(delta)
This was the most significant engineering challenge.
Streaming from Zed isn’t like streaming raw LLM output. An LLM token stream is purely append-only. Zed’s agent panel isn’t — a single response turn contains an assistant message, tool calls with status indicators, and follow-up messages, all interleaved. Those status indicators mutate in place mid-stream: **Status: Running** becomes **Status: Completed**. Content can change anywhere, not just at the end.
The naive approach — send the full accumulated response on every update — worked, but scaled badly. On every message_added event (dozens per second during fast token streaming), the API would:
Query the database for the session
Query the database for the interaction
Write the updated interaction back
Serialize the entire interaction as JSON and publish it to the frontend
For a 100KB response, this meant pushing 100KB over the WebSocket on every token. By the end of a long response, the browser was doing megabytes of string copying per second and the UI would visibly lag.
Caching and throttling (Go side): A streamingContext struct caches the session and interaction for the lifetime of a streaming response, eliminating two database round-trips per token. Database writes are throttled to one every 200ms — the in-memory state always has the latest content, but we only flush to Postgres periodically. message_completed always writes the final state, so at most 200ms of content is lost on a crash. Frontend publishes are throttled to one every 50ms, since the frontend batches to requestAnimationFrame (~16ms) anyway.
Patch-based deltas: Instead of sending the full interaction JSON on every update, the API computes a patch — the byte offset of the first change and the new content from that point forward. In the common case (pure append), the fast path fires: check that the new content starts with the previous content, return the offset and the suffix. One string prefix comparison.
For backwards edits (tool call status changing), the slow path finds the first differing rune.
The frontend receives interaction_patch events and applies them directly to a ref, bypassing React state during streaming. Multiple patches between animation frames are coalesced. The React Query cache isn’t touched until completion.
Wire traffic: O(N) per update → O(delta). For a 100KB response where each token adds ~20 bytes, that’s roughly a 5000x reduction per update.
Bug 3: The UTF-16 Offset
The first deployment of the patch protocol produced garbled text. Users saw "de Statussktop" where "desktop" should have appeared. Content in the database was correct — corruption was purely in rendering.
The root cause: computePatch returned byte offsets (Go’s len() counts bytes), but JavaScript string.slice() operates on UTF-16 code units. The streaming content contained 147 instances of › (U+203A, RIGHT SINGLE ANGLE QUOTATION MARK — Zed uses this as a breadcrumb separator in tool call output). Each › is 3 bytes in UTF-8 but 1 UTF-16 code unit, creating a cumulative offset divergence of 294 bytes. When a backwards edit occurred — a tool call status change — the patch was spliced into the wrong position.
The fix iterates by rune and tracks UTF-16 code unit position:
go
func utf16RuneLen(r rune) int {
if r >= 0x10000 {
return 2 // surrogate pair
}
return 1
}The slow path decodes runes from both strings in lockstep, accumulating utf16Off alongside byteOff. Supplementary plane characters (emoji like 📤) count as 2 UTF-16 code units.
Zed-side throttling: Zed fires an EntryUpdated event on every LLM token. At high token rates, that’s hundreds of message_added messages per second, most of them redundant since the Go side only publishes every 50ms anyway. A 100ms throttle in Zed’s thread_service.rs buffer,s intermediate update,s and flushes before every message_completed. Nothing is dropped; wire traffic drops by ~90%.
The overall shape of the work: fork a fast editor, add a protocol layer, find three distinct bugs each caused by a different mismatch between assumptions (overwrite vs. append semantics, session-level vs. interaction-level events, byte offsets vs. UTF-16 code units), then fix the performance problem that only appears at scale. Standard distributed systems work, with a Rust/Go language boundary making everything a bit more interesting.
Code is available at github.com/helixml/helix.