
How we got fine-tuning Mistral-7B to not suck: Helix Project Report, Feb 2024
Announcing Helix v0.5 with improved text fine-tuning and OpenAI API support 🎉

Hi folks,
It’s been just over a month since we launched Helix v0.1, and today I’m happy to announce today the availability of Helix v0.5. Run it yourself on your own secure private infrastructure or try it out on our SaaS:

Along with a shiny new UI (you can a screenshot for comparison in our first post), we’ve been extremely focused on improving the quality of the text fine-tuning.
tl;dr
We made text fine-tuning not suck
Try it here: + New Fine Tune
Tell us what you think on Discord!
“The doctors are going to perform a tracheostomy”
When we first launched Helix, the text fine tuning of the Mistral-7B-Instruct language model was based on this LlamaIndex docs page. Yeah, we basically decided to build a whole business around one this LlamaIndex notebook.

At the time, unfortunately I hadn’t even seen the link from the parent page in the LlamaIndex docs that said “WIP: this isn’t very good yet”. Uh-oh.

Of course, because Helix is targeting being runnable fully on-prem, we’re using Mistral-7B with axolotl for fine-tuning instead of the GPT-3.5 API, but it’s the same principle. The idea is that you chunk your documents up into pieces, then ask a language model to generate question-answer pairs (which is the shape of the training data you need to provide the fine-tuning process). You’re using an LLM to automate generating training data for fine-tuning another LLM. The original prompt looks like this:

Did it work? Sorta, but it was a bit crap. Just like LlamaIndex said it would be.
We were able to feed it complex technical papers, and it was able to answer technical questions about them. But it failed at some much more basic tasks.
This one news article for example: Junior doctors in England to stage more strikes over pay. This article became the bane of my life for a few weeks 😂
Why? Because when we first asked the fine tuned model the simple question:
Question: What are the doctors going to do?
Answer: The doctors are going to perform fine-tuning on data to improve the accuracy of the model
What?! You were fine-tuned on information derived from the article. Why are you talking about fine-tuning?!
–me
OK, turned out this one was fairly straightforward. One of the text elements meant to tell the user “fine tuning completed” was also being sent back to the model as if the user had said it. Now the only context the model had to go on was the idea of fine-tuning. We got that one out of the way. Cool, let’s try again:
Question: What are the doctors going to do?
Answer: The doctors are going to perform a tracheostomy
OMG, seriously? Surely you should know that the doctors are threatening to go on strike. It’s right there in the title! Stupid fine-tuning, maybe it will never work. 🤬
–me
But we persisted. OK, so why isn’t the model able to answer questions about the basic context of the article? Well, it’s because the question-answer pairs generated by the prompt aren’t in the form of simple questions about the title of the document. The solution, it turned out, was rather than a single qapair generating prompt, we had to implement a suite of them, to extract context from the document from all sorts of different perspectives: what are the entities in the document and how are they related? What’s a short, medium and long summary of the document? Who/what/where questions, etc. See the full list here.
Turns out, when we carefully constructed this suite of prompts, we were then finally able to get the model to answer the basic question about “what are the doctors going to do?” Phew! 😅
Document IDs aren’t just for RAG
Our other insight was that by generating a content-addressed hash for each document, we could also teach the model about the IDs of the individual documents, along with IDs for groups of documents.
We can then map those IDs back onto the documents the model was fine-tuned on. For example: in this session the model is able to tell you that what it’s learned was in a given document, even linking the user back to that document. I also found this exchange pretty hilarious:

Although maybe that says more about my sense of humour than anything else.
We then added a system prompt telling the model to refer only to the specific document IDs it was trained on and not to refer to background knowledge. What do you know, it worked!
How do you know when you’re good?
So far we’re adjusting the prompts and system for this LLM app based on “vibes”. That is, trying stuff, evaluating it by eye, and then changing it. Problem is, vibes don’t scale.
Vibes don’t scale
Work is ongoing on an end-to-end “evals” framework so we can automatically build up a library of good and bad sessions, and then every time we change the prompts, code, model etc re-run the fine-tuning across all of the sessions in the library, and then grade them. We might even use an LLM to grade them automatically :-)

Please help us by clicking the new thumbs up and thumbs down buttons at the bottom of your sessions! We’ll use these as input to improve the product.
Why not just use RAG?
Oh believe me, we’ve talked about it. We’re sticking with fine-tuning for now, because:
Fine tuning can memorize far more information than you can fit in a single prompt
By not needing to cram any custom knowledge in the prompt, you can get much better latency
Fine tuning is better at copying style (we have qapair prompts planned for this)
Fine tuning is better at understanding a large corpus of background knowledge (a “domain”) and being able to draw on all of it when constructing an answer
Fine tuned models are easier to run at the edge without needing the infrastructure of vector stores close to the model
You can use a much smaller fine-tuned model than general purpose model plus RAG. What can you do with a fine-tuned Phi-2 model that can run on any CPU?
We made it work!!
Are we wrong? Come and roast us on Discord!
OpenAI API Support
We now have an OpenAI compatible API. For example, here I am configuring Flowise to integrate with my private Helix deployment, for example:
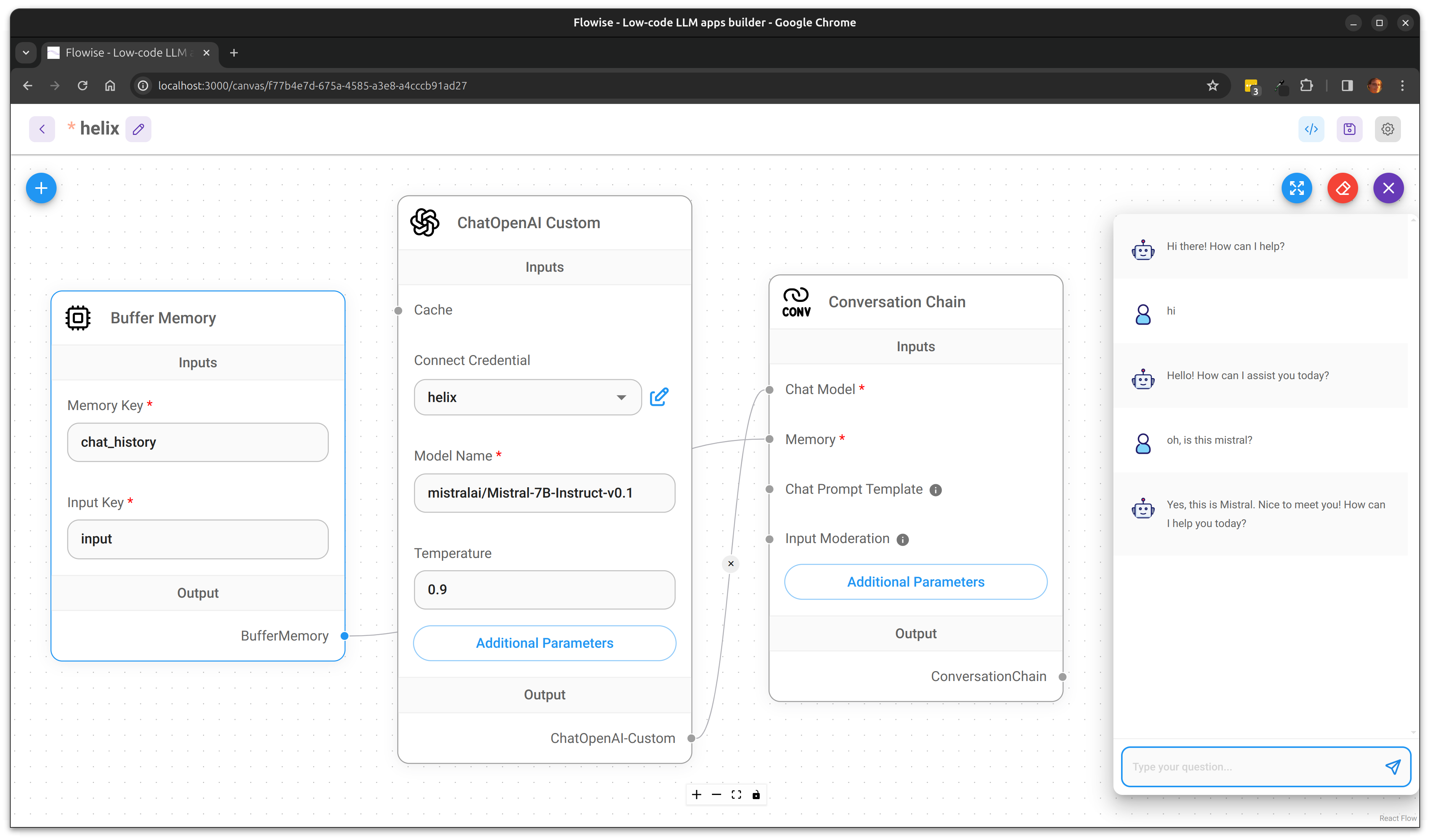
Just set:
Model Name: mistralai/Mistral-7B-Instruct-v0.1
Connect Credential: Your API key from https://app.tryhelix.ai/account
BasePath (under additional parameters): https://app.tryhelix.ai/v1
And that’s it! You’ll notice your API calls to Helix show up as sessions in your account, so you get a free record of them :-)
Other small things:
We’ll automatically fine tune the model once the qapairs are extracted, then email you when it’s finished. We hope this will encourage more people to dive back into the app once you’ve waited the 10-15 minutes it takes to train your own AI.
Thanks for reading! Soon I’ll blog more about our roadmap, on-prem use cases where we’re seeing significant commerial traction, and our dirty secret. Subscribe and stay in the loop :-)
What?! You were fine-tuned on information derived from the article. Why are you talking about fine-tuning?!
😂
This is a great read Luke
This is absolutely amazing! Great job!