
The Unexpected Benefits of Self-Hosting Your LLM
And Some Lessons Learnt From The Cloud Native Community

I had a lightbulb moment when I first realised you could host your own LLM, on your own Kubernetes cluster. Having spent 15 years in enterprise IT, the appeal of self-hosting was obvious: security, data protection, and data sovereignty. The important stuff that makes sure your CISO can sleep soundly at night.
But, one year on I’ve realised the opportunity is a bit larger than simply “How do I deploy this LLM thingy?” While building a platform around open LLMs HelixML ended up in familiar territory, thinking about Developer Experience. It was fantastic to share this story at KubeCon London alongside Luke Marsden.
Lessons Learnt From A Decade of Kubernetes
This week, at KubeCon in London, I was reflecting on the early days of Kubernetes adoption. Every team running their own carefully misconfigured cluster, each one a beautiful snowflake of technical debt. It seems history has a funny way of repeating itself. Welcome to 2025, where "AI sprawl" is the new "kubesprawl," and everyone's favourite hobby is spinning up their own unique LLM implementation, RAG pipeline or chatbot.
The movement towards centralised Platform Engineering has helped us to tame the kubesprawl chaos, and our platform teams have an important role to play in GenAI adoption too. They just may not know it yet.
Watching teams reinvent the RAG pipeline over and over again in the name of innovation is going to get old very quickly. It turns out that bringing order to AI chaos is remarkably similar to bringing order to container chaos. Who would've thought?
Platforms That Delight Developers
The goal of a successful platform is to deliver a secure, reliable and delightful service to the developers who use it, making it easier for them to ship applications for their end users. We find ourselves at an interesting moment in time where these development teams have new, emerging needs as they begin to integrate LLMs into their applications. Has your platform team recognised this need? Can we skip the “AI sprawl” and build a Developer Experience around these new architectures? I think we can, and we should.
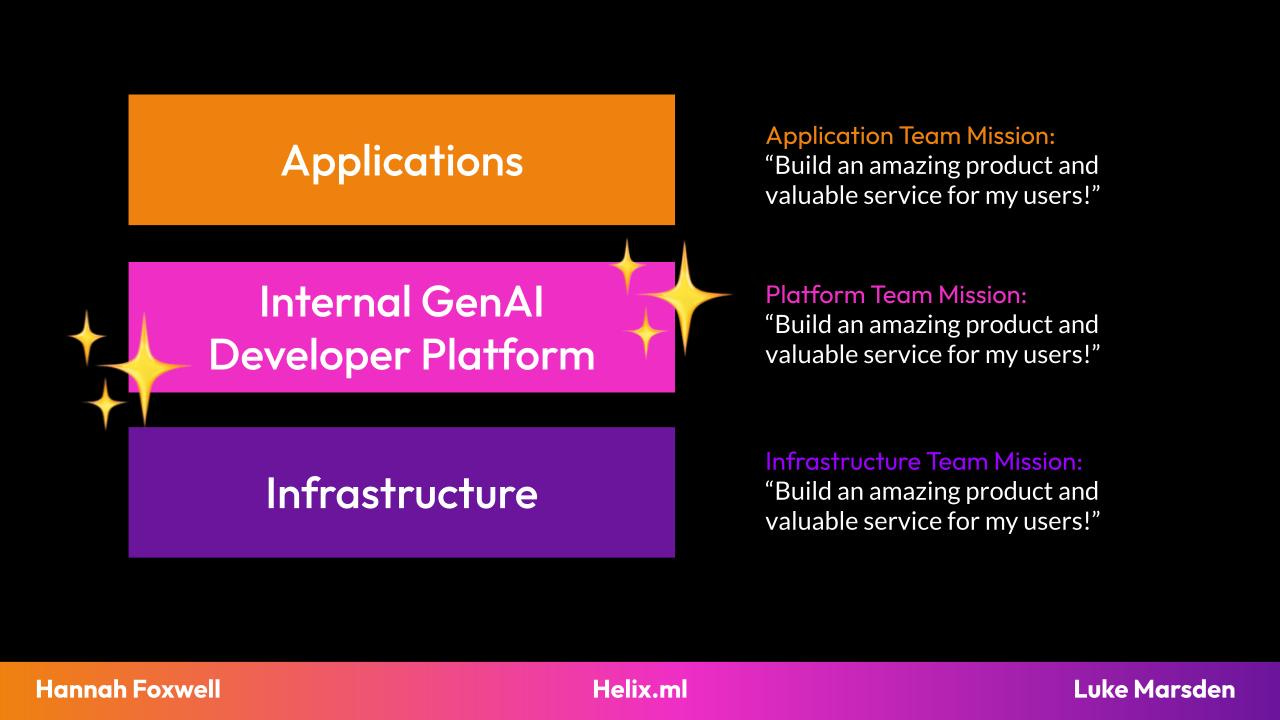
Your self-hosted LLM needs to be consumable “as-a-service” on your platform. We know from a decade of Kubernetes that self service is the key to Developer Productivity. Instead of your dev teams spending three sprints figuring out how to build and manage a vector database, or wrestling with GPU optimisation, they should be able to consume AI capabilities through a secure, standardised, self-service platform.
With Helix we extended the capabilities from just LLMs by creating standardised RAG pipelines. This popular pattern of augmenting the LLM with your business knowledge and context has so many practical applications. We don’t want every team building their own unique flavour of RAG when they could be focusing on actual business problems.
(If you missed the demo of the very shiny new Vision RAG pipeline at KubeCon be sure to subscribe so we can share our talk as soon as that recording is available!)
Select The Right Model For The Job
Breaking news! Large Language Models are … Large. Who knew?!
Importantly though, Large Language Models are not always the right tool for the job. One other unexpected benefit of self-hosting is the ability to use smaller models. If you’re building an application that helps developers find information in your internal wiki, then you might not need the model to also know “how to plan a road trip across France” or “how to poach an egg”.
Think of small models like slim container images. Only ship what you actually need! The trend towards slim container images reflects the maturity of our container ecosystem - bloated base images were an issue for everyone. And the same principle applies here with language models; not every AI use case needs a model that has memorised the entire internet!
Using a smaller model requires less energy and is often more efficient, so you get a system that’s simply lighter and faster. You can’t do that if you’re consuming your LLM through a SaaS or Cloud API. Another benefit of self-hosting!
Path To Productivity with GenAI
I talk to a lot of Platform Engineers who provide training, documentation and advocacy for their Internal Developer Platforms (IDP) as part of the Platform Team’s responsibilities. The teams who do this have been successful in supporting developers on their “path to productivity” with containers and Kubernetes and they have a role to play in the adoption of GenAI and Large Language Models too.
Embracing Platform Engineering for GenAI can help developers get started with a new domain, abstracting away a lot of the complexity and allowing them to focus only on the parts that really matter to them.
Oh and $$$… That’s A Thing
Another benefit of self-hosting is, of course, money! What if you didn't have to count tokens like a miser counting pennies? With self-hosted models it’s not “pay as you go” and in many ways you’re motivated to use more. You don’t want those expensive GPUs sat about idle do you?
We’re excited about the future of Platform Engineering for self-hosted LLMs and we want to make it as easy as possible. Helix helps you build and manage your GenAI platform on your existing Kubernetes cluster. Check out the project here on GitHub