
What a control room for AI coding agents actually looks like
Most teams run one AI coding agent at a time on a developer’s laptop. Helix gives each agent its own GPU-accelerated desktop, then lets you orchestrate dozens of them in parallel


What a control room for AI coding agents actually looks like
Picture ten items on your engineering backlog. A new feature. A framework migration. Four security patches. A batch of logging improvements across a dozen repos. You know the shape of every one of them. You could write specs for all of them this afternoon.
You can’t build them all this afternoon. Not with one developer. Not even with one very good AI agent.
Helix changes that equation. Not by making one agent faster, but by giving you a fleet of them, each working in its own GPU-accelerated desktop, coordinated through a Kanban board you can watch in real time.
Each agent gets its own computer
We covered this architecture in an earlier post, but it’s worth repeating here because it’s the foundation everything else builds on.
Every agent in Helix gets its own isolated desktop environment. Not a container with a language runtime. A full GPU-accelerated Linux desktop running the Zed code editor, a terminal, a browser, and its own filesystem. When you spin up five agents to work on five tasks, they’re running on five separate desktops. They can’t interfere with each other.
Each desktop appears as a separate machine, but underneath it’s a high-density Docker-in-Docker (or Docker-in-Kubernetes) setup sharing GPU resources. We did a lot of work on GPU virtualization with virtio-gpu and Vulkan passthrough to make multi-tenant desktops viable on a single physical machine.
The result is that you can watch your agents work. Literally watch them. You see the code editor, the terminal output, the browser window. When an agent opens Chrome to test the app it just built, you see Chrome open. When it reads an error and goes back to fix the code, you see that too.
The Kanban board
The orchestration layer is a Kanban board. Columns for backlog, planning, implementation, review, and done. Each card is a task. Each task gets an agent.
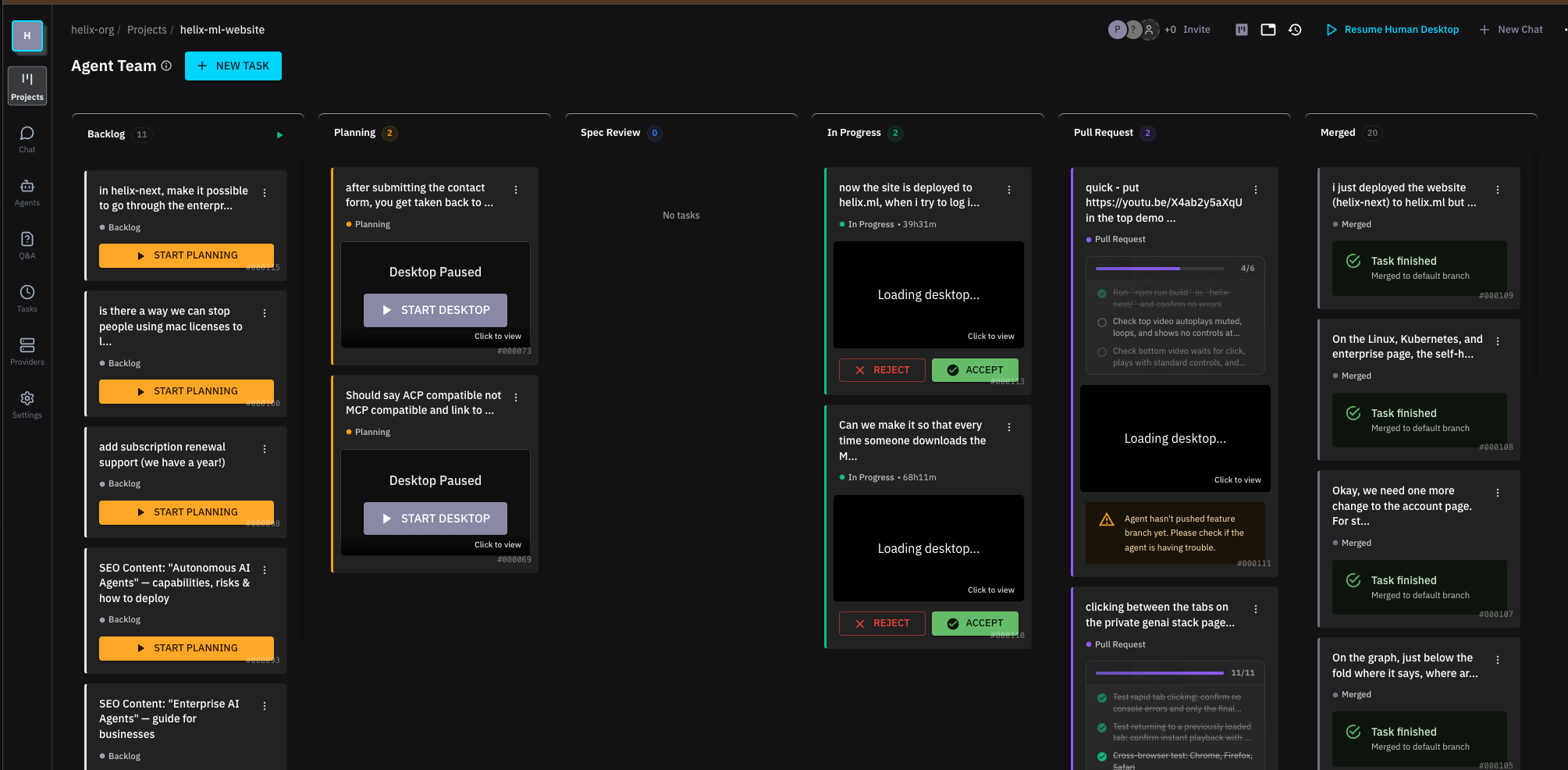
Move a card into the planning column and the agent spins up a desktop and starts writing a spec. As with Spec Driven development: requirements first, then technical design, followed by an implementation plan (spec). The agent writes these documents in Zed, and you can review them with inline comments, Google Docs style. Leave a comment saying “what about edge cases for deleted users?” and the agent responds to your comment and updates the design.
This is the workflow that’s changed how we build software internally. You batch up your thinking early. Leave comments on specs across five different tasks. The agents respond and iterate on the designs while you move on to the next review. When a design looks right, you approve it, and the agent shifts into implementation mode. It writes code, runs tests, and opens a pull request.
The approval of the implementation plan isn’t ceremonial. When you approve a spec, the agent receives a structured prompt telling it: “Your design has been approved. You’re now in the implementation phase.” File diffs show up in real time. The agent commits code, runs the app, and tests it. You’re reviewing finished pull requests, not babysitting the work.
Agents don’t talk to each other (on purpose)
The obvious question with multiple agents: if one miscommunicates something to another, how do you debug that?
Our answer is that they don’t communicate with each other. At all.
For coding tasks, where an agent needs to hold a coherent plan from spec to implementation, the communication overhead with multi agent communication buys you very little and introduces failure modes that are genuinely hard to debug.
So our agents are intentionally isolated. They coordinate the same way human developers do: through git. When an agent finishes its work and opens a pull request, it merges from main first. If there’s a conflict, it resolves it. That’s the coordination mechanism. It’s boring. It works.
Maybe one day it’ll make sense to have two agents pair-programming on the same desktop. But right now, isolated agents working in parallel on separate tasks, coordinating through version control, gives you the throughput gains without the chaos.
Do the work once, apply it everywhere
Some of the most valuable engineering work is also the most tedious: applying the same change across dozens of repositories.
Think about an organisation with 100 repos that share the same Python framework. Same patterns, same structure. A security patch or logging change needs to go into 30 or 50 of them. That work goes on the backlog. And it sits there. For weeks. Sometimes months.
Here’s what we built. You do the work once, in one repo, with one agent. During that process, the agent learns things you didn’t know at the beginning. The spec gets refined through actually doing the work. Then you clone that refined spec across the other 49 repos. The agents spin up in parallel, each working in its own desktop, each applying the same pattern to a different codebase.
Do one in an hour. Do 49 in ten minutes.
Not all of them land perfectly. You review a group view that shows progress across all the cloned tasks: which ones are done, which ones need attention, which ones have already been merged. But the ratio of human effort to output changes dramatically. Instead of a new hire spending a week getting through three of them, you’re reviewing pull requests across all 49 by lunchtime.
The acceleration curve
We have adopted this concept called the AI acceleration curve from Steve Yegge’s post from Jan 2026. It’s eight steps, from basic model inference all the way up to orchestrated agent fleets.
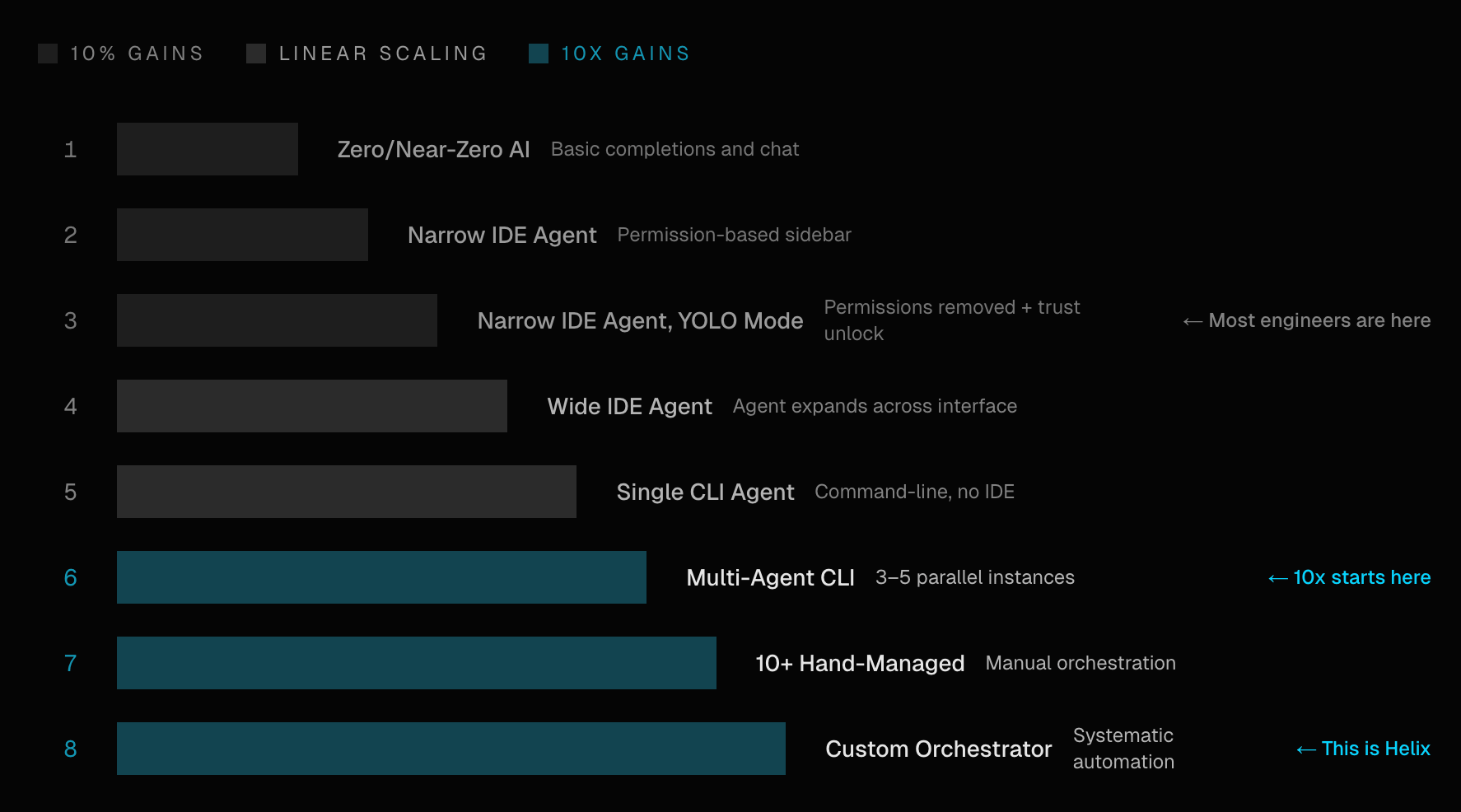
The instinct is to skip straight to step eight. Everybody wants the fleet.
But the reality is that a team running its first inference endpoints this quarter is the team that’ll be ready for agent fleets next year. Each step builds the organisational muscle, the infrastructure, the trust, that makes the next step possible.
Helix Coding agents are built for step eight. But Helix works at every step along the way. You can start with self-hosted inference and RAG. Add single-agent coding sessions when your team is comfortable. Move to multi-agent orchestration when you’ve seen enough to trust the workflow.
That’s not a compromise. It’s how platforms actually grow. You meet teams where they are. You solve the problem they have right now. And when they’re ready for the next level, the infrastructure is already there.
Try it
If you want to see where your team falls on the curve, or you just want to watch five AI agents build five different apps at the same time, we’d love to talk.